ACloudGuru AWS Lambda Notes

Lambda
You lose control over the environment. You have to use what they provide. Lambda is a function as a service tool.
It isn't serverless in itself but it is apart of a serverless architecture.
- Serverless is about APIs
- Avoid solving the same problems
- Own your app, not your dependencies
Pay as you go. Pricing matches usage
Functions as a Service
EC2 vs. Lambda
Why Lambda
- simplicity
- save $$$
- easy for ops
- easy for devs
Use cases
- ETL Jobs
- APIs (with API Gateway)
- Provides Http frontend for Lambda function
- Mobile Backends
- Infrastructure automation
- Data validation
- Can use like a stored procedure to validate DynamoDB data
How Lambda Works
You are using containers that are run on EC2 instances which are not accessible by you. The containers are resource isolated. 100ms timeouts (which can be configured; they terminate regardless of the state of your process).
Application is composed of:
- Code (and dependencies)
- Event
- Schedules
- S3 Events
- DynamoDB Streams
- Kinesis Streams
- SNS Topics
- API Gateway
- SDK Invocation
- Output (what your function sends back; either to an external service)
Example Workflow
- S3 is an object store
- Lambda an receive events
- Code is stateless
- Node.js, Python, or Java (any JVM language, Scala or Clojure)
- Event happens
- Function receives event
- Custom code runs
Some event -> some code runs -> some actions happen
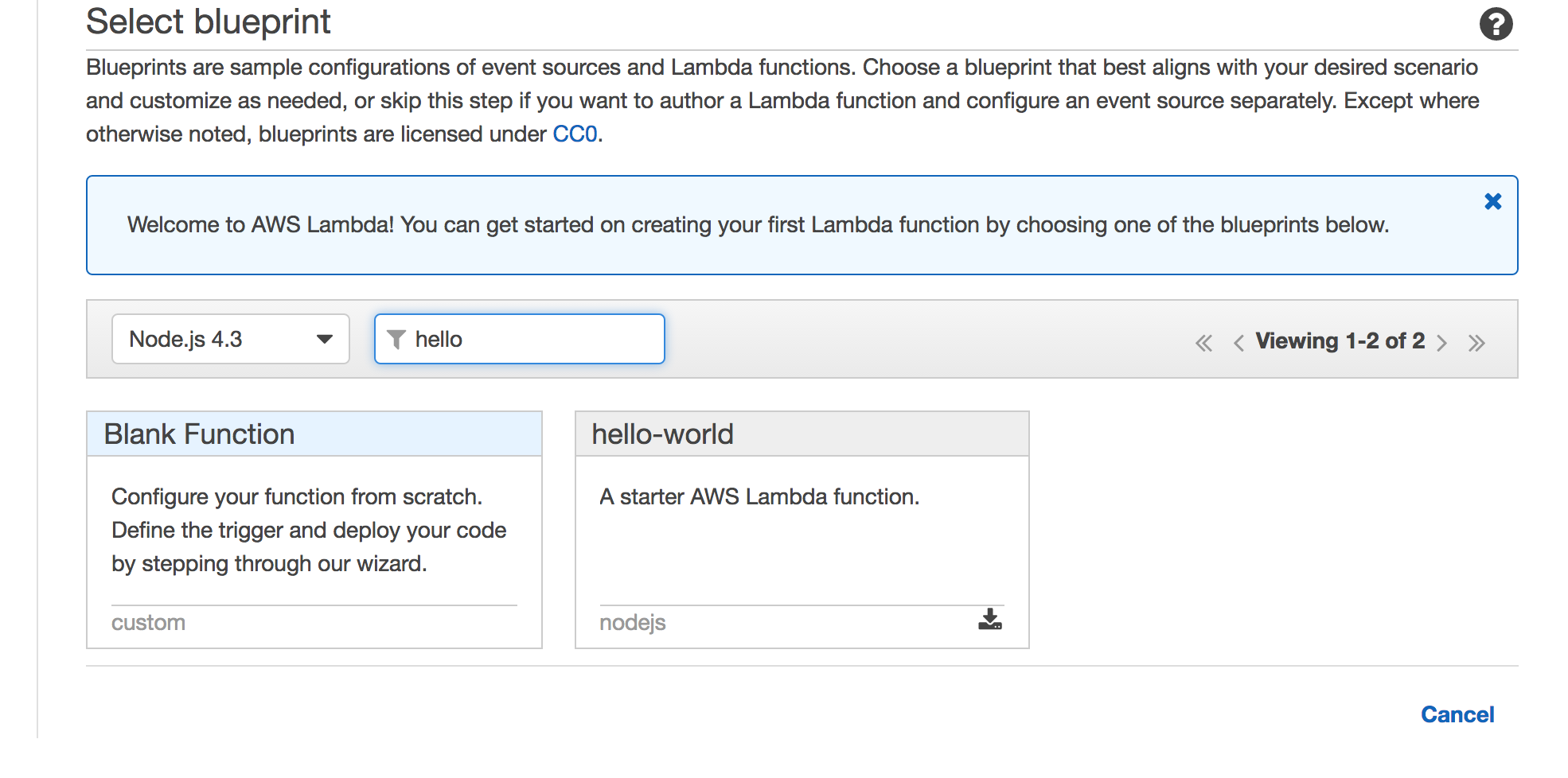
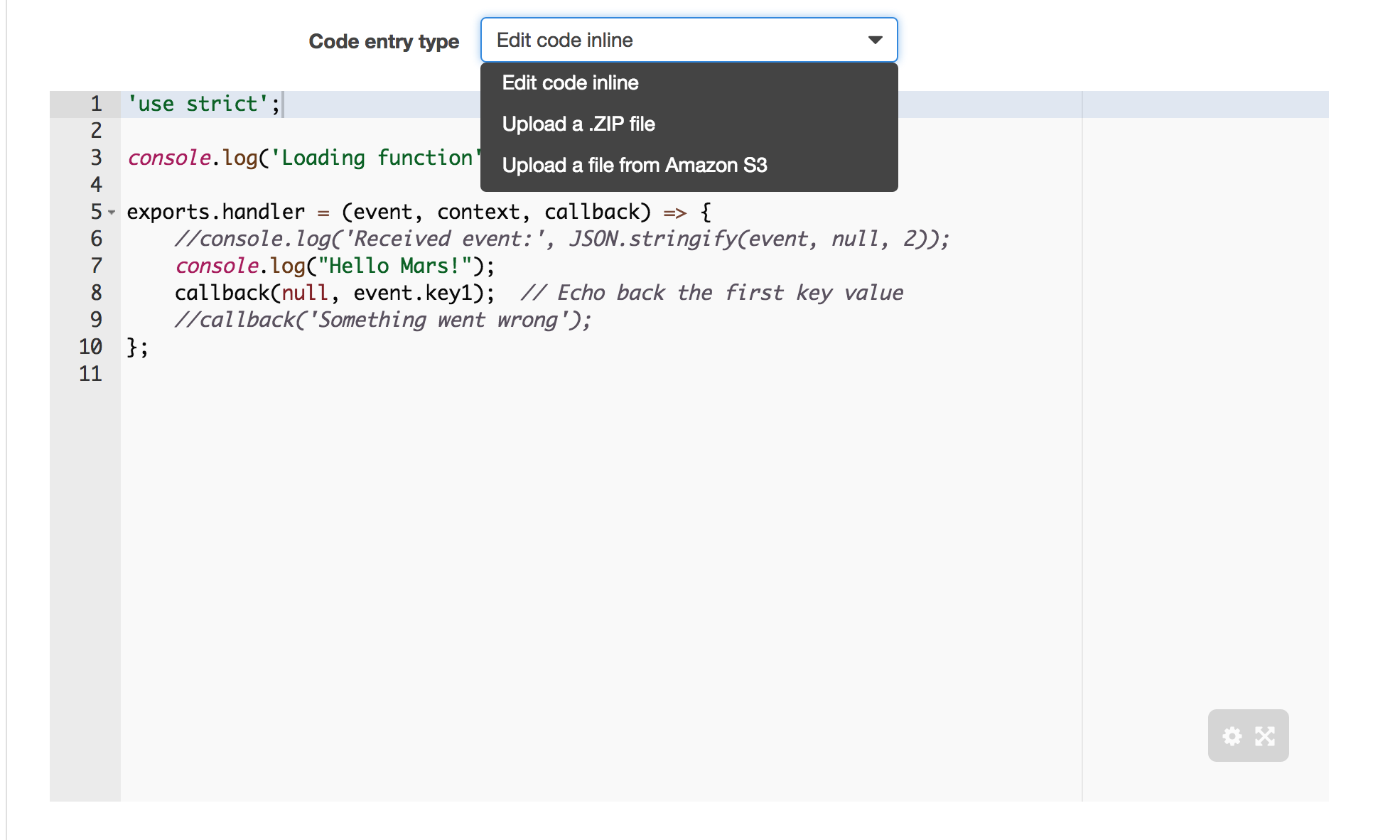
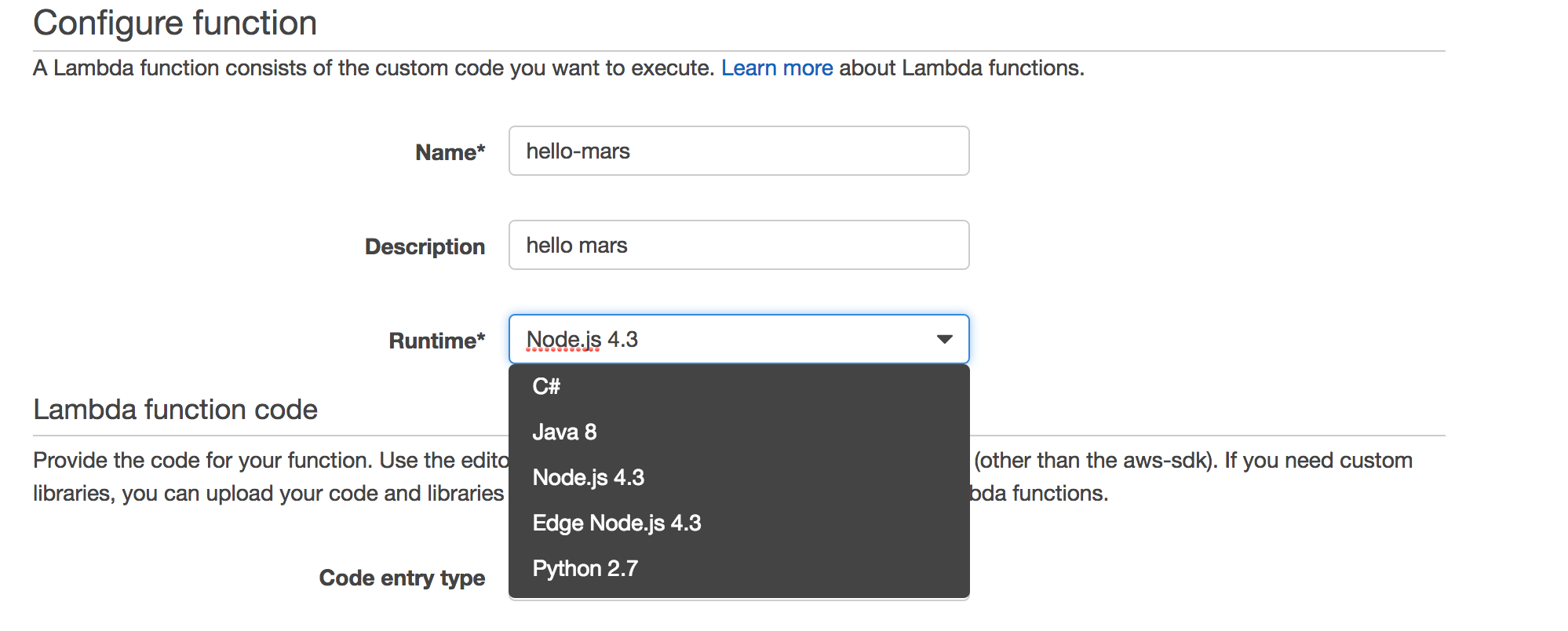
Lab 0 -- Hello World
Every Lambda function has a handler that is a mapping to:
- path to the function to be run
- Must accept 3 args: event, context, and callback
- Uses index.js by default (node)
exports.handler = function(event, context, callback) {
console.log("Hello Mars!");
return callback(null, "Yo!");
}
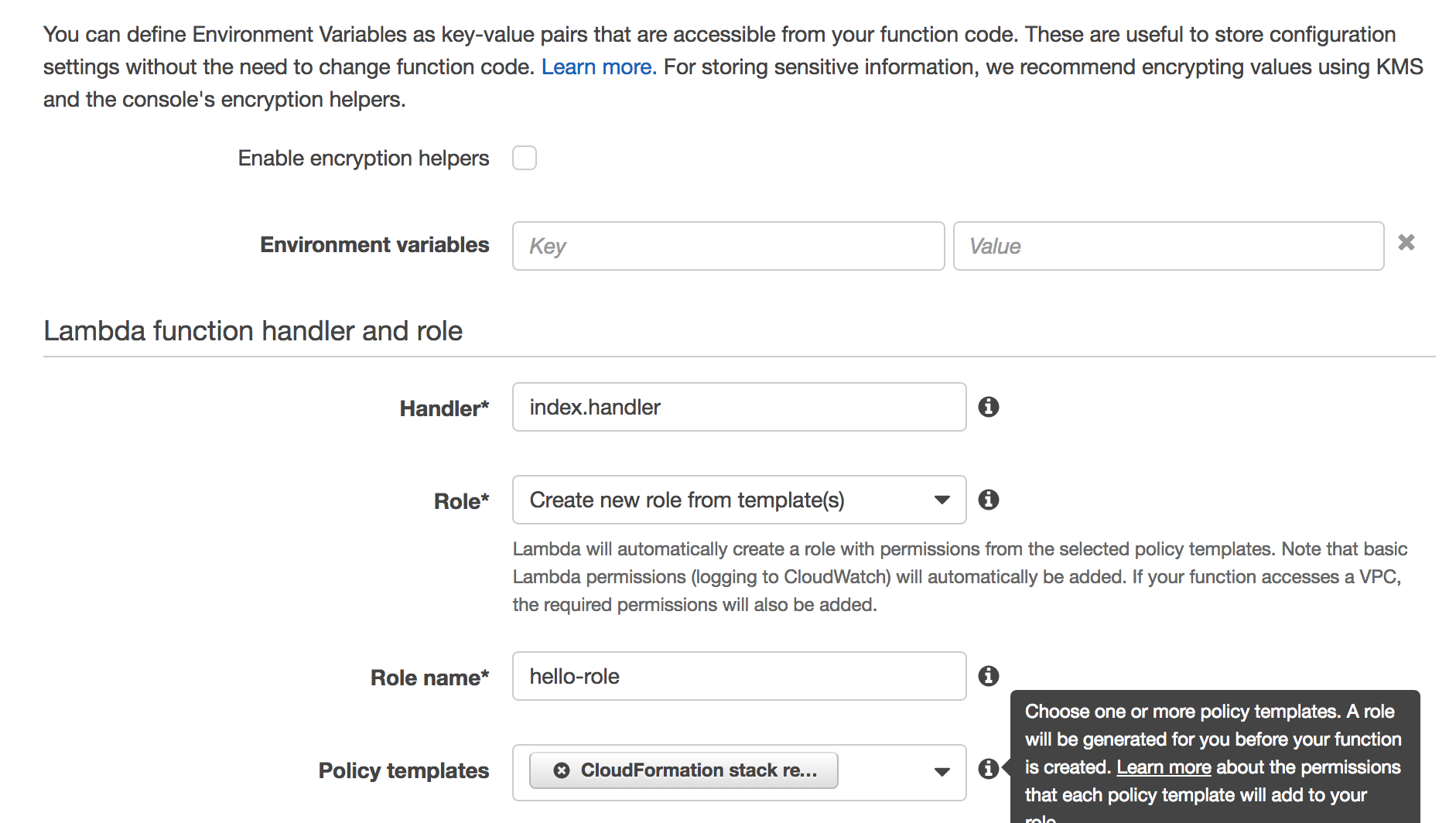
IAM
A role can have many policies. policies have statements.
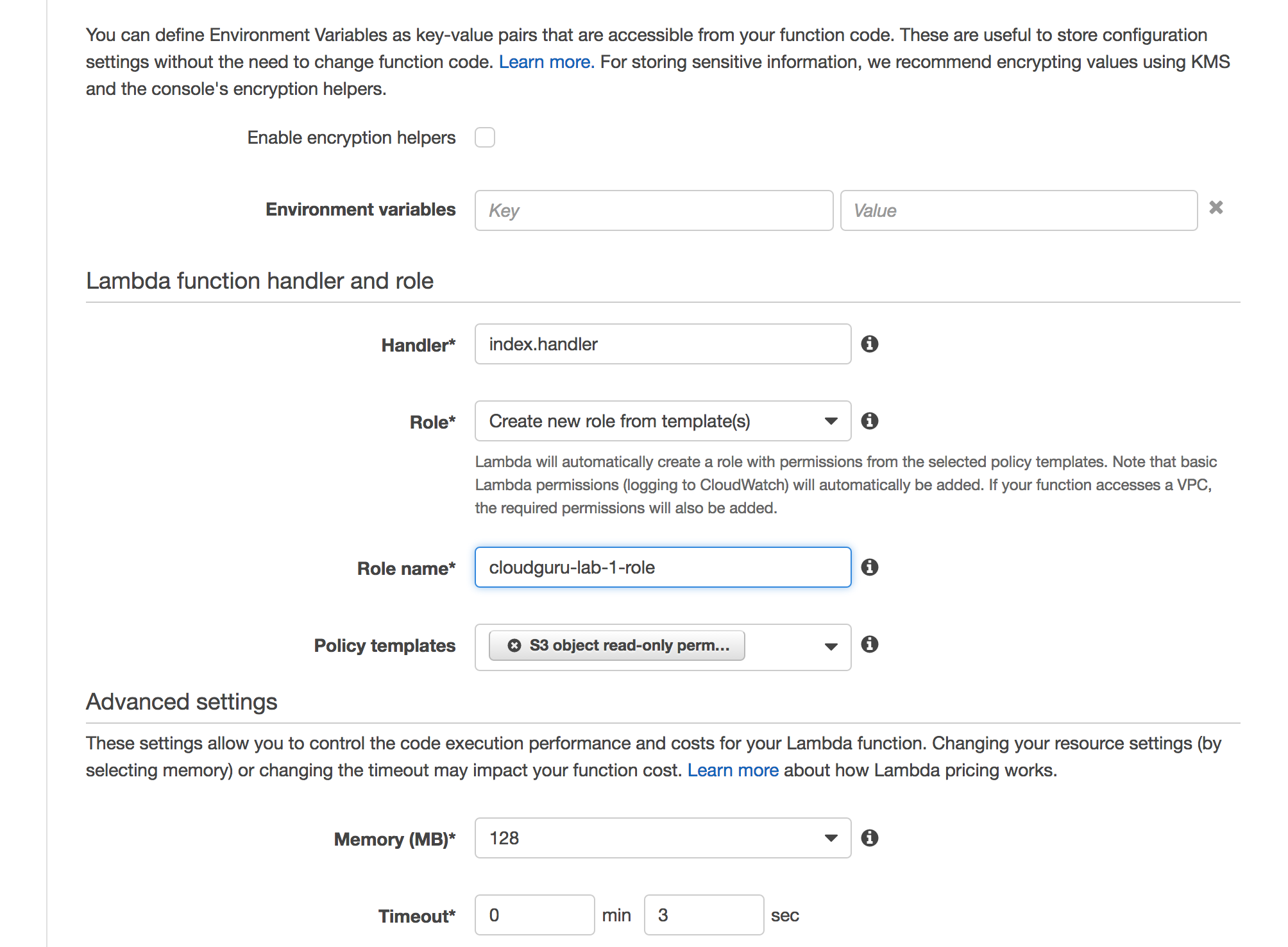
A common way to name roles is on the job that it is doing.
i.e. an image-processor role.
CPU Performance and Lambda
Memory is what changes the cost. The CPU scales with memory. Up to 1.5 GB of memory.
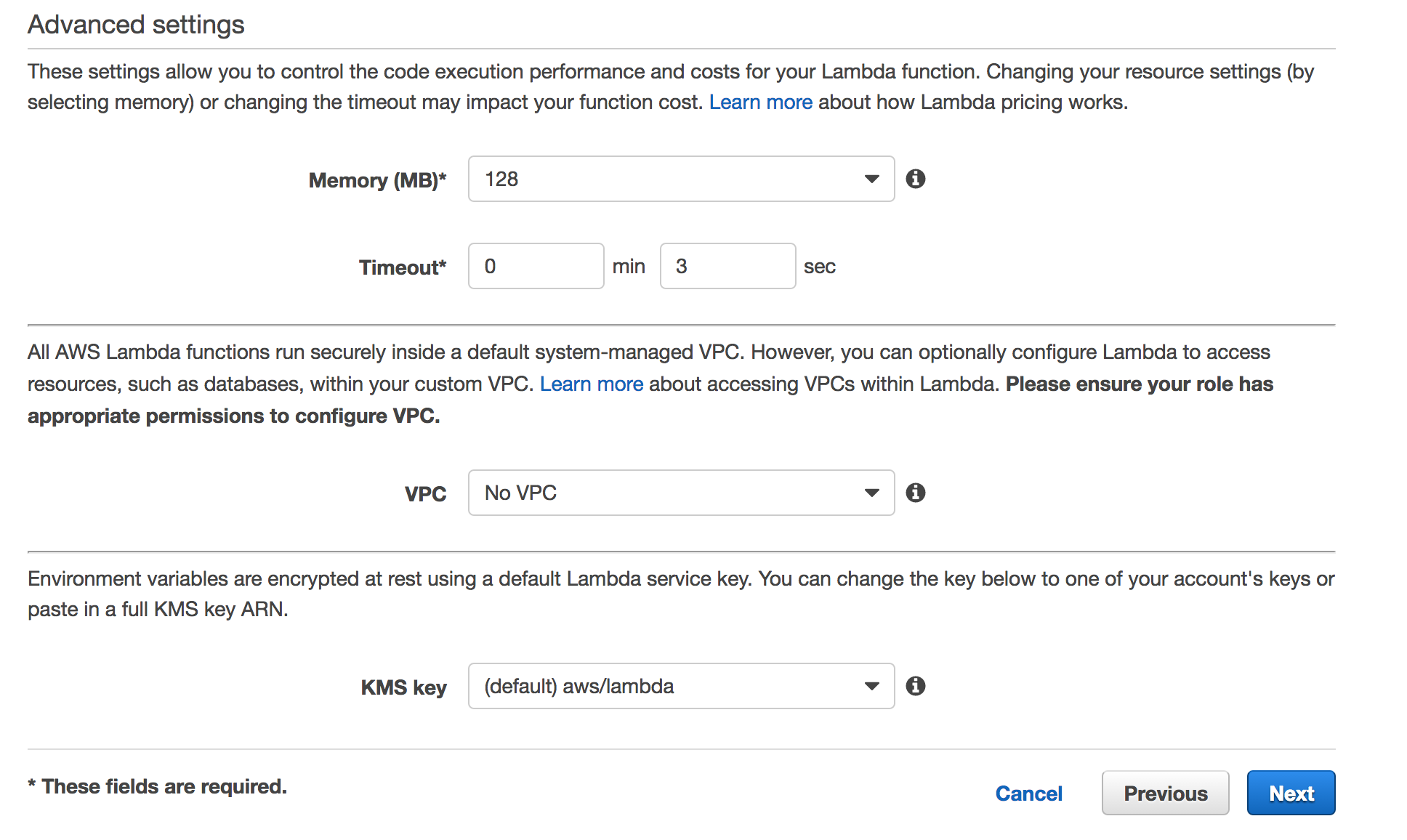
Finish Creation
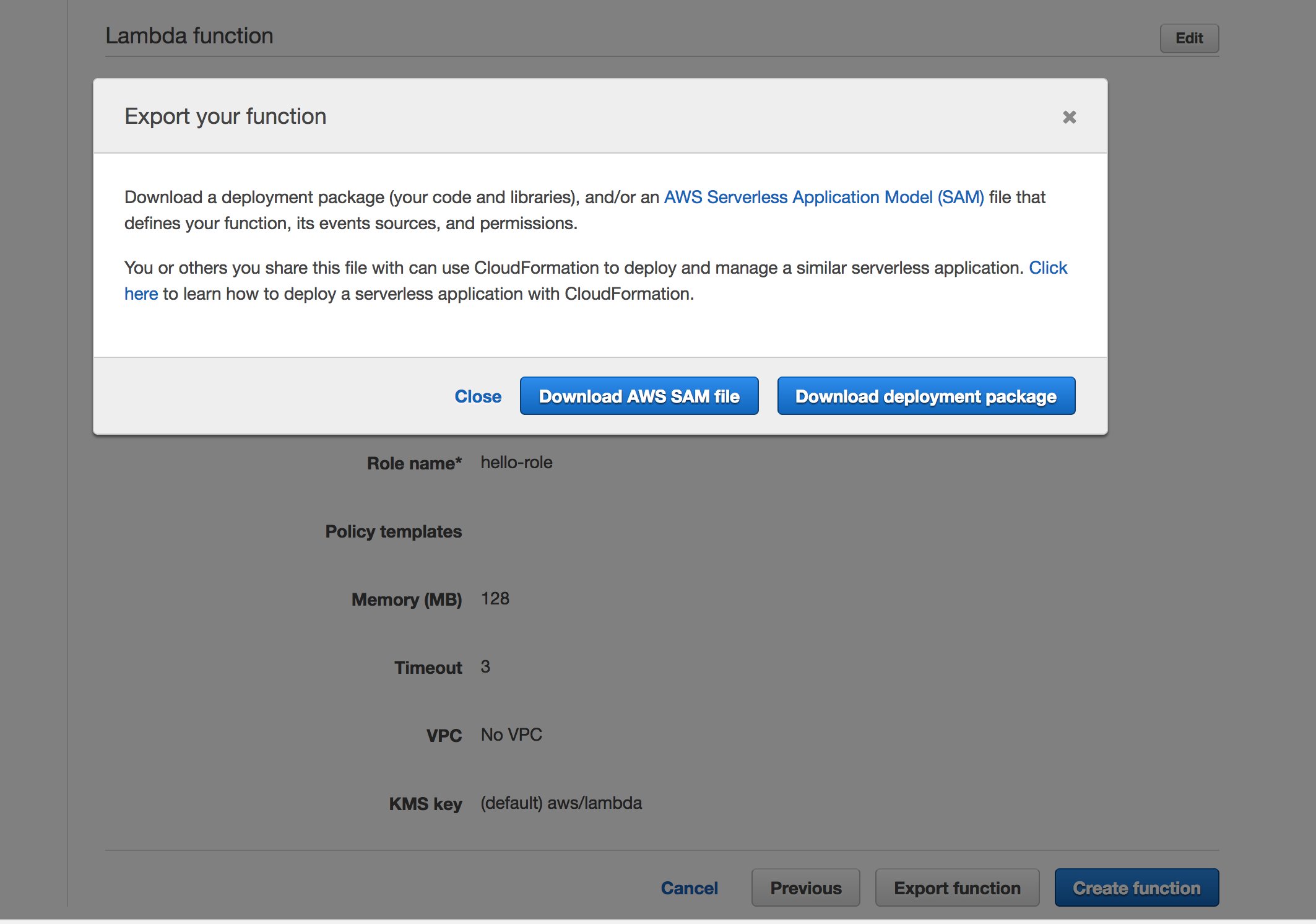
Export the function:
Test the function:
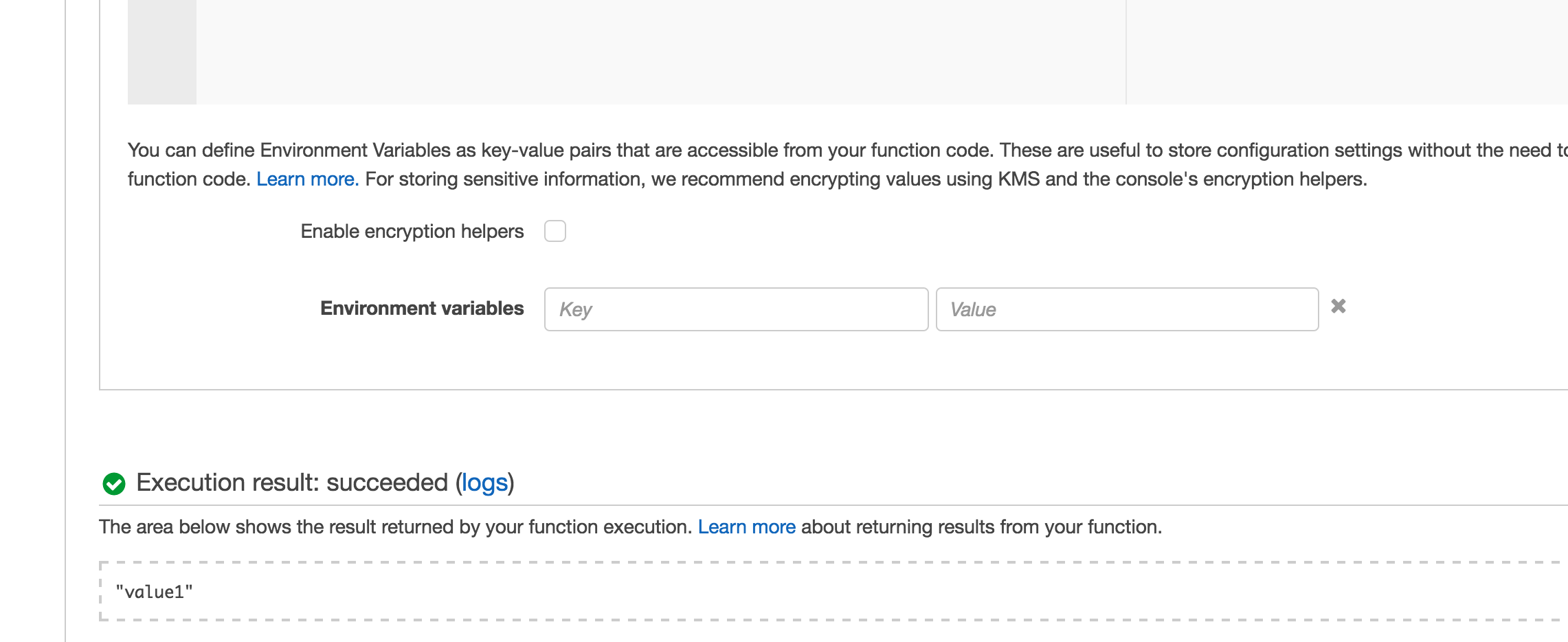
And the test succeeded:
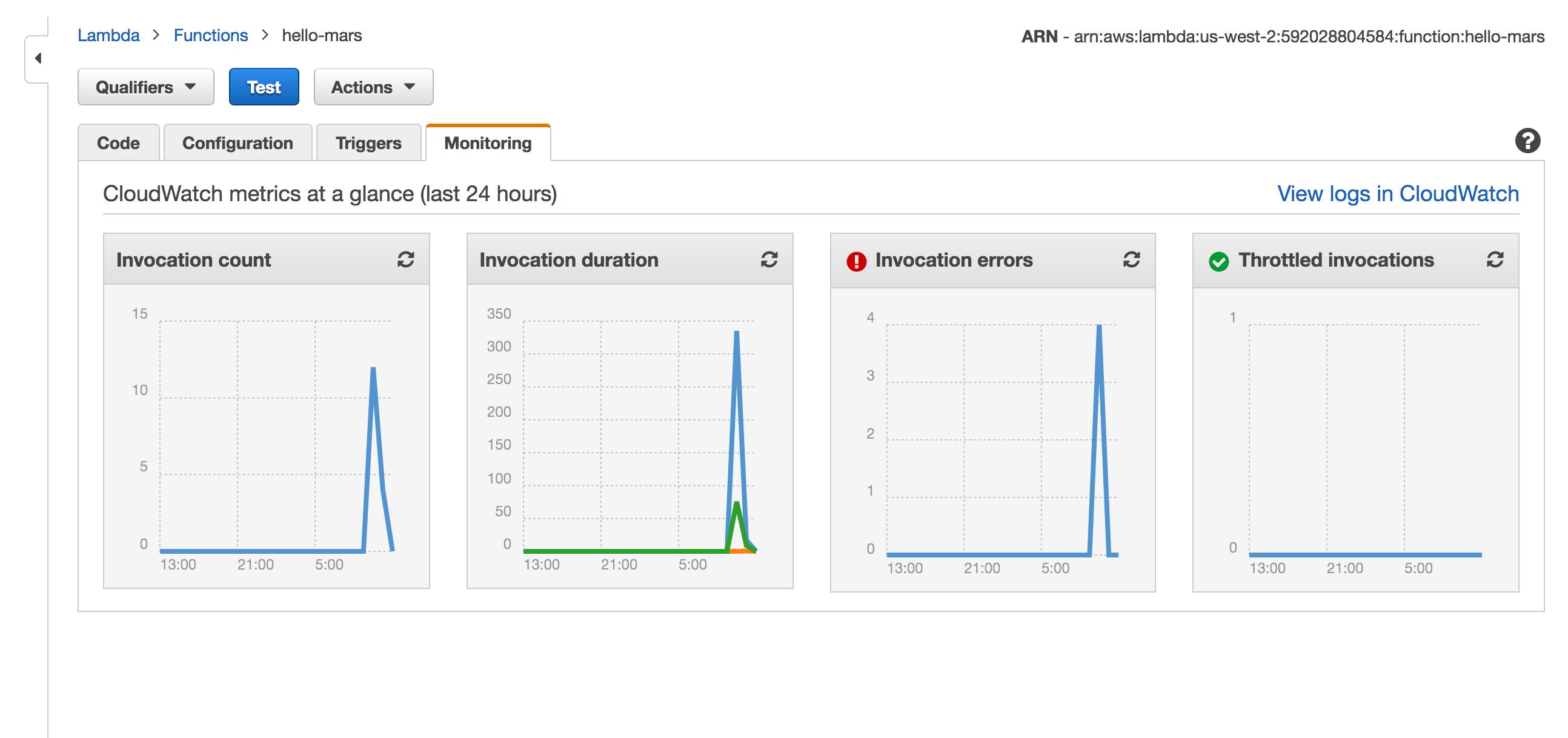
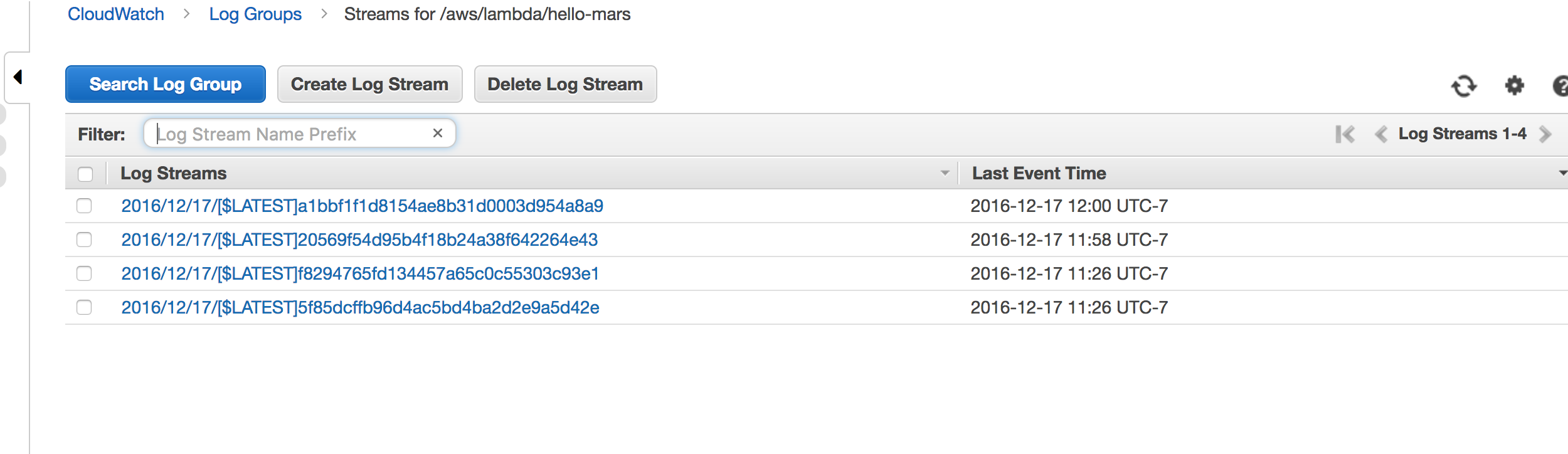
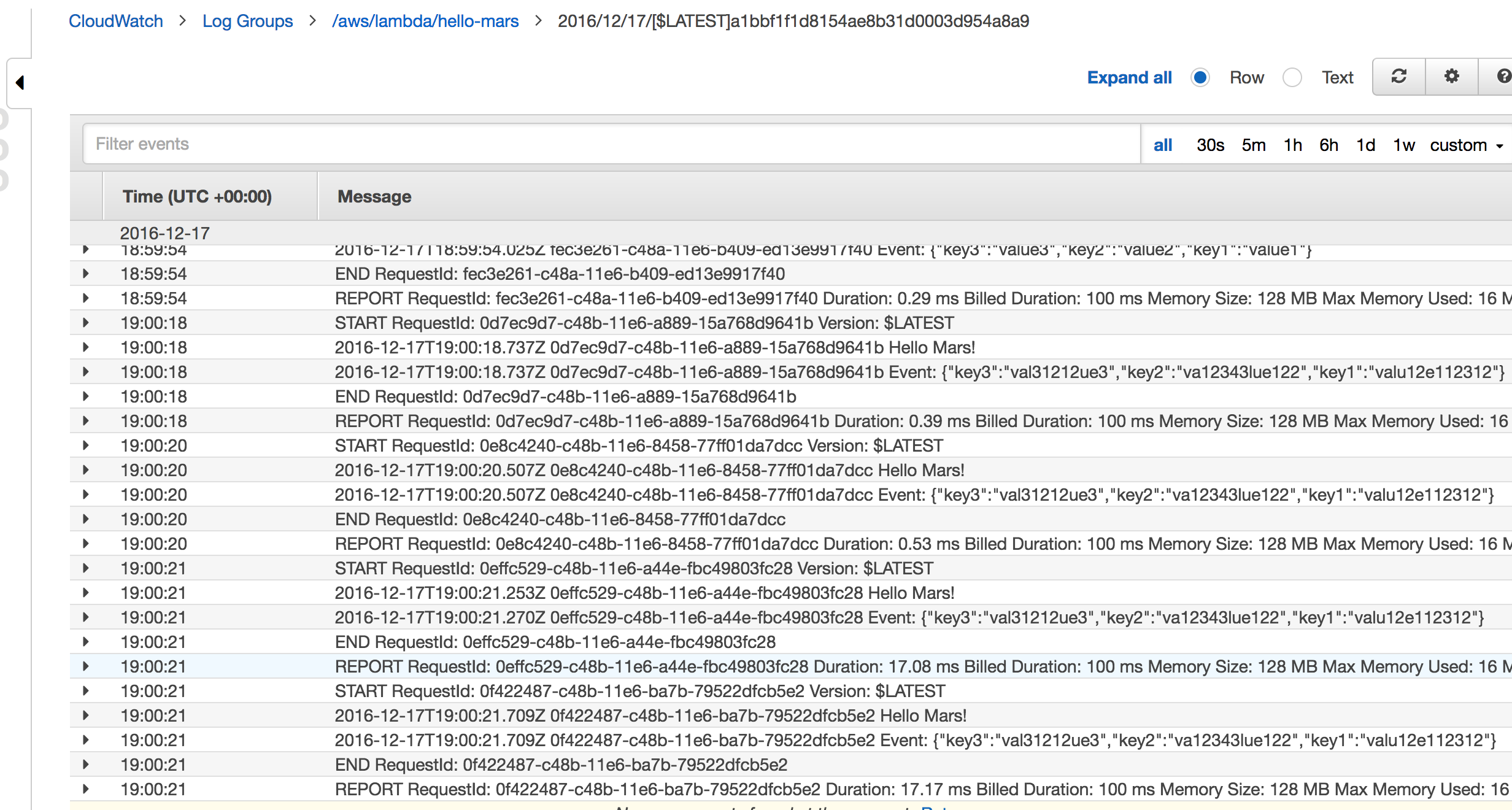
Wiring up CloudWatch
Cloudwatch logs are automatically collected and stored, searchable, and timestamped automatically.
Lab 1
S3
Make the bucket
aws s3 mb s3://adw-lambda-labs
aws s3 cp sample.csv s3://adw-lambda-labs
Use a blank function definition
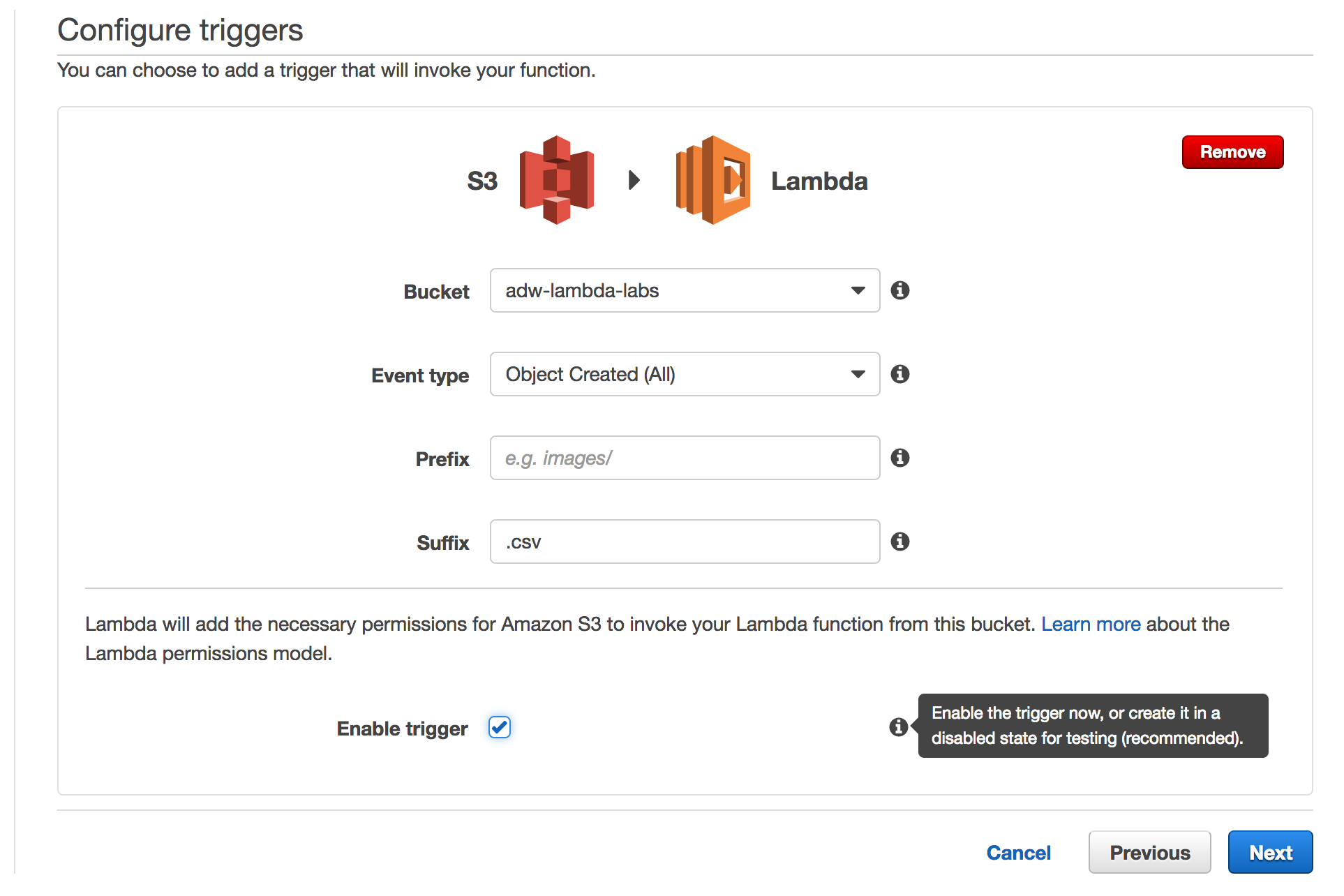
Set the event trigger.
Event types are the events that you can receive in your Lambda function. For this lab, we'll use object created.
We'll be restricting the suffix to .csv
Searching for the Trigger:
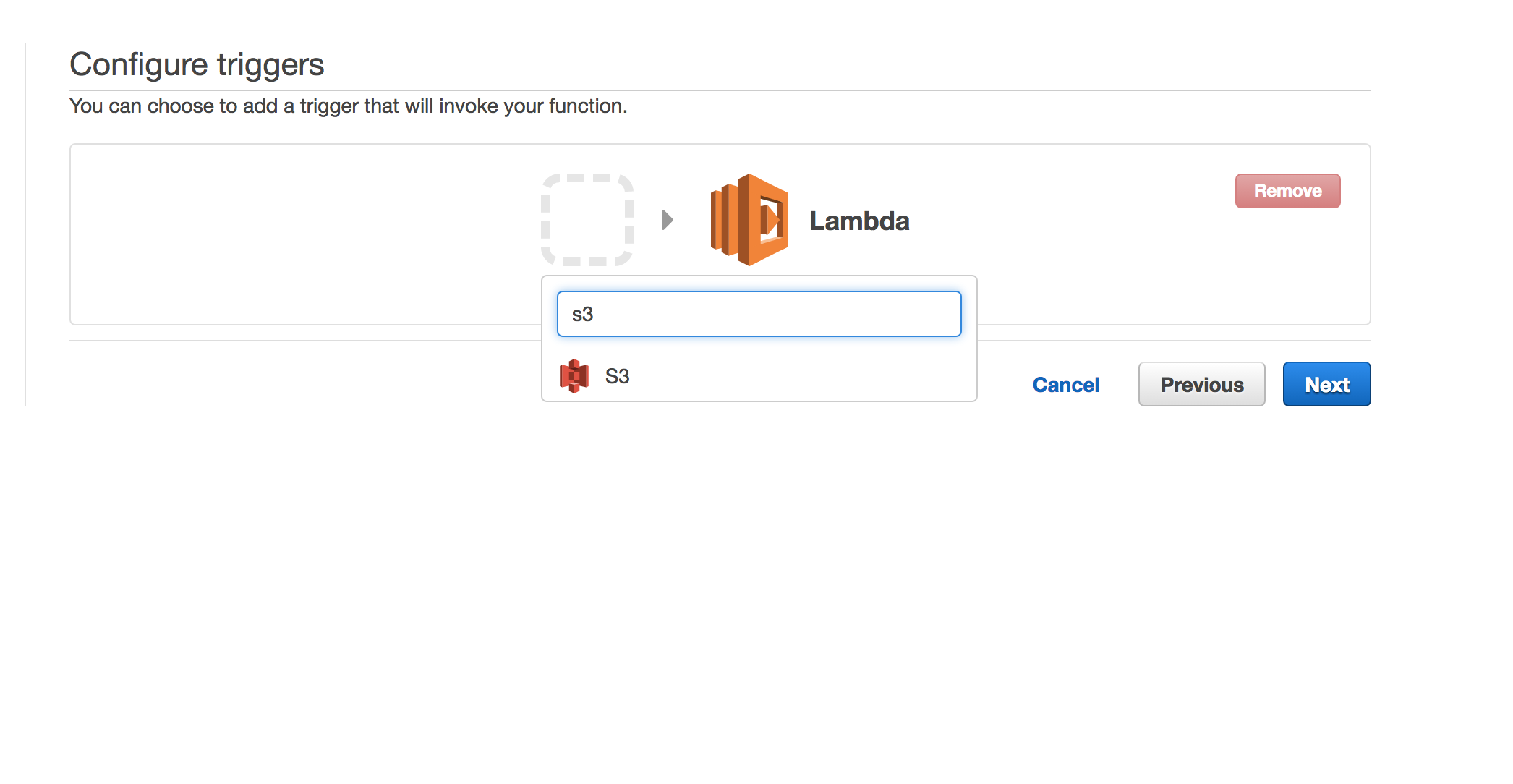
S3 Trigger Filled Out:
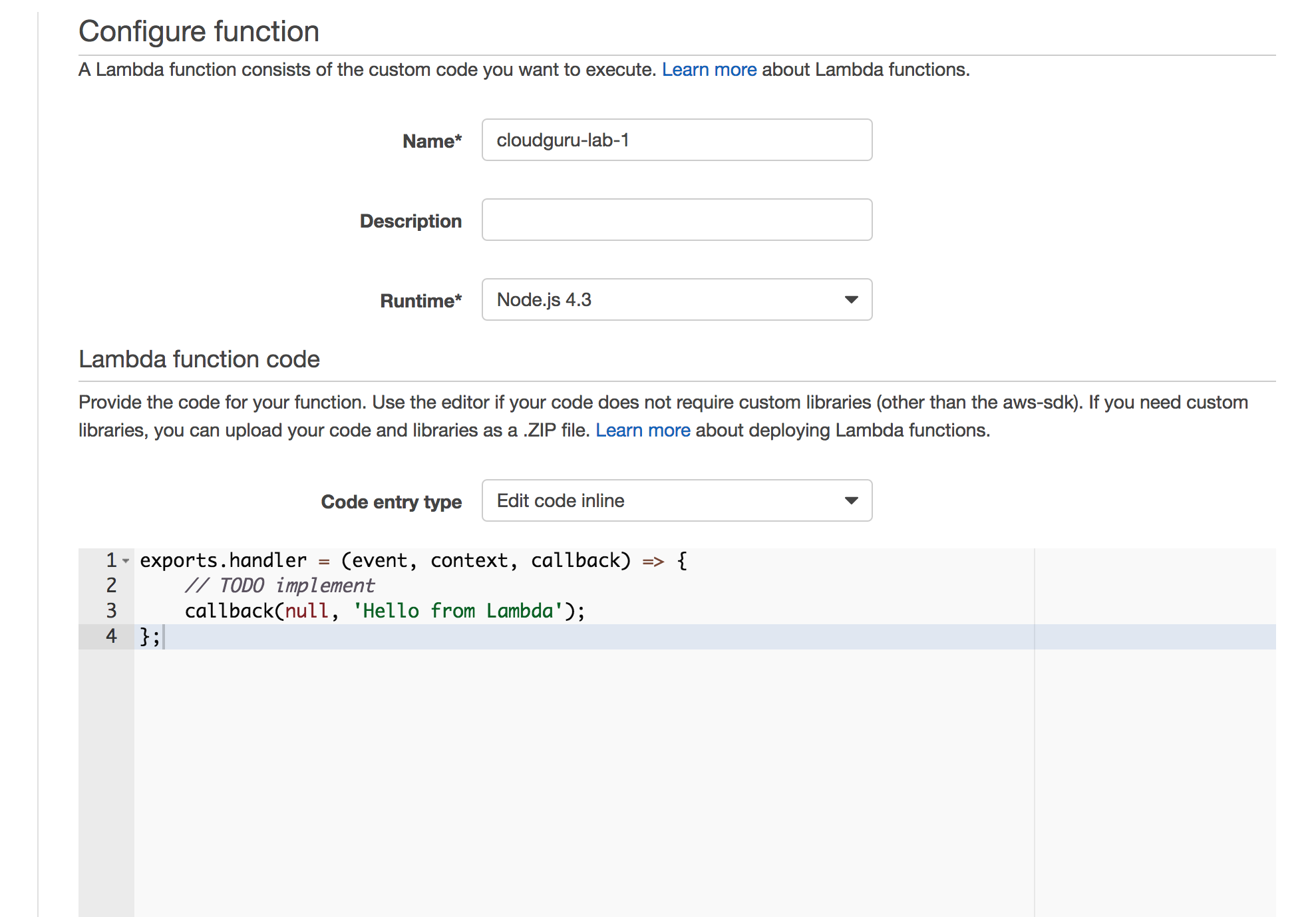
Function definition:
Role:
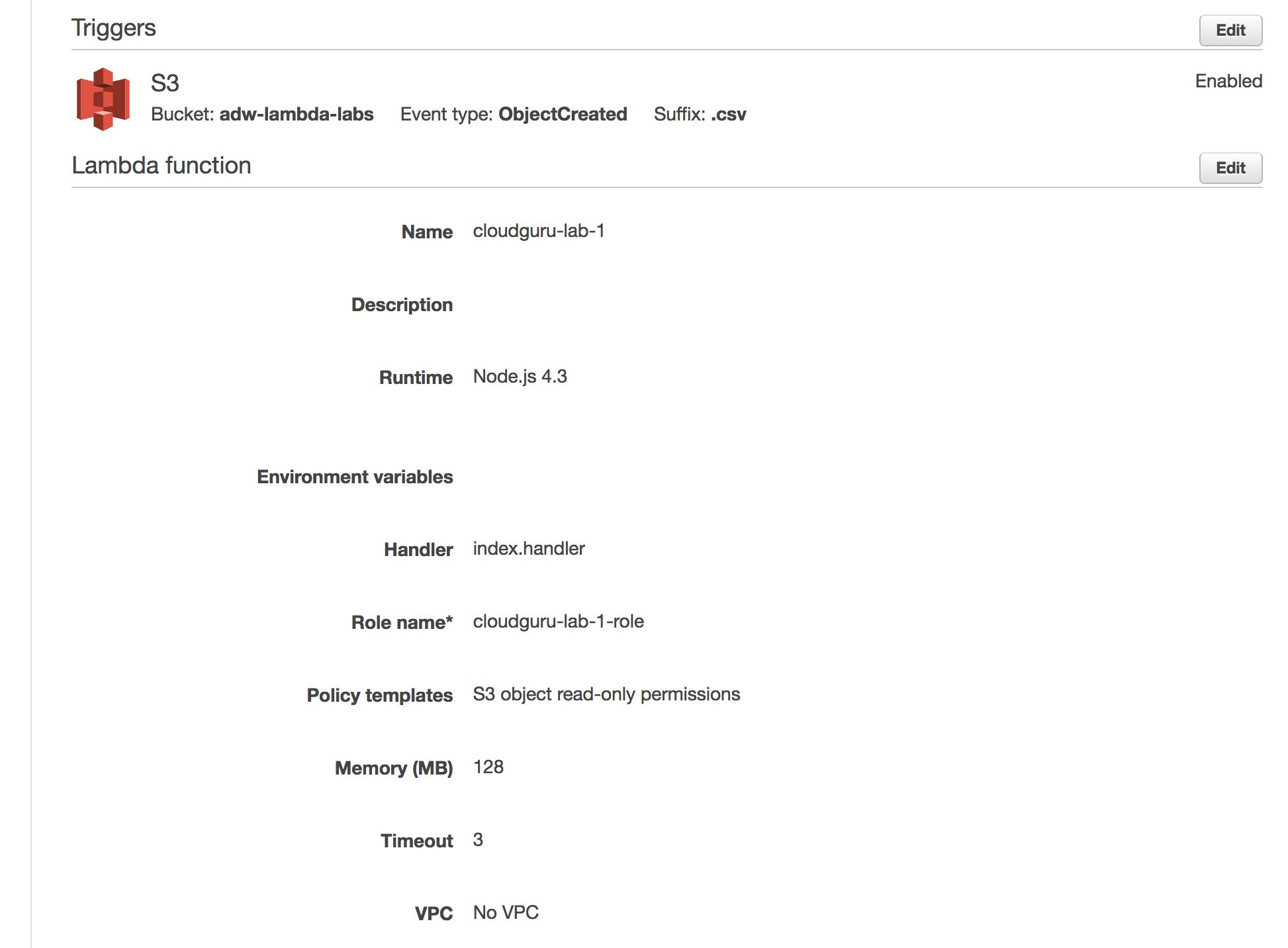
Complete:
Upload code using Zip file:
aws lambda update-function-code --zip-file=fileb://csv_parse.zip --function-name cloudguru-lab-1
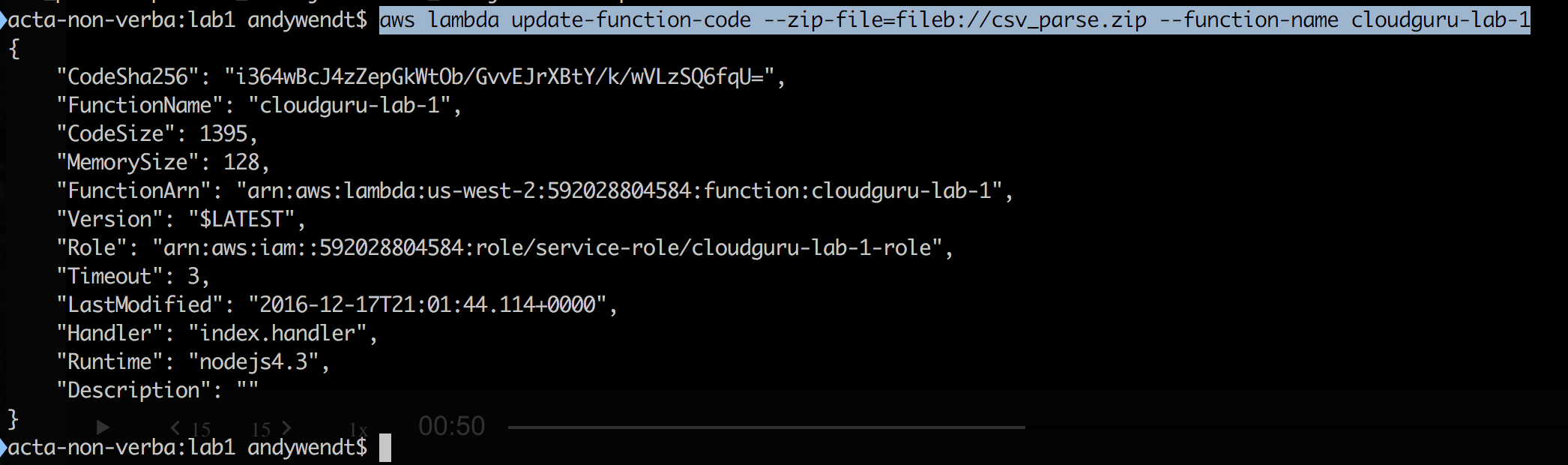
Update handler to match zip file:
aws lambda update-function-configuration --function-name cloudguru-lab-1 --handler csv_read.handler
{
"CodeSha256": "i364wBcJ4zZepGkWtOb/GvvEJrXBtY/k/wVLzSQ6fqU=",
"FunctionName": "cloudguru-lab-1",
"CodeSize": 1395,
"MemorySize": 128,
"FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-1",
"Version": "$LATEST",
"Role": "arn:aws:iam::592028804584:role/service-role/cloudguru-lab-1-role",
"Timeout": 3,
"LastModified": "2016-12-17T21:06:21.781+0000",
"Handler": "csv_read.handler",
"Runtime": "nodejs4.3",
"Description": ""
}
Updated Test:
Test Result:
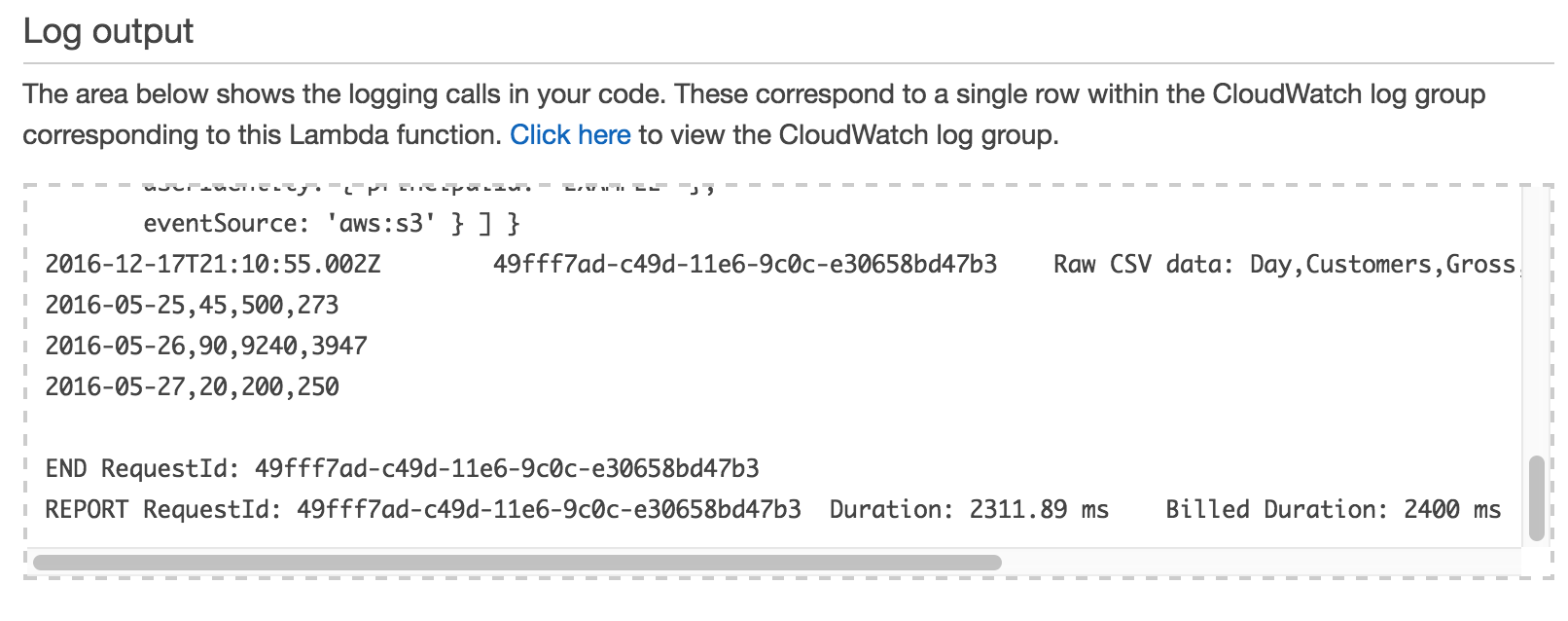
Try another upload and then check the logs:
aws s3 cp sample.csv s3://adw-lambda-labs/sample2.csv
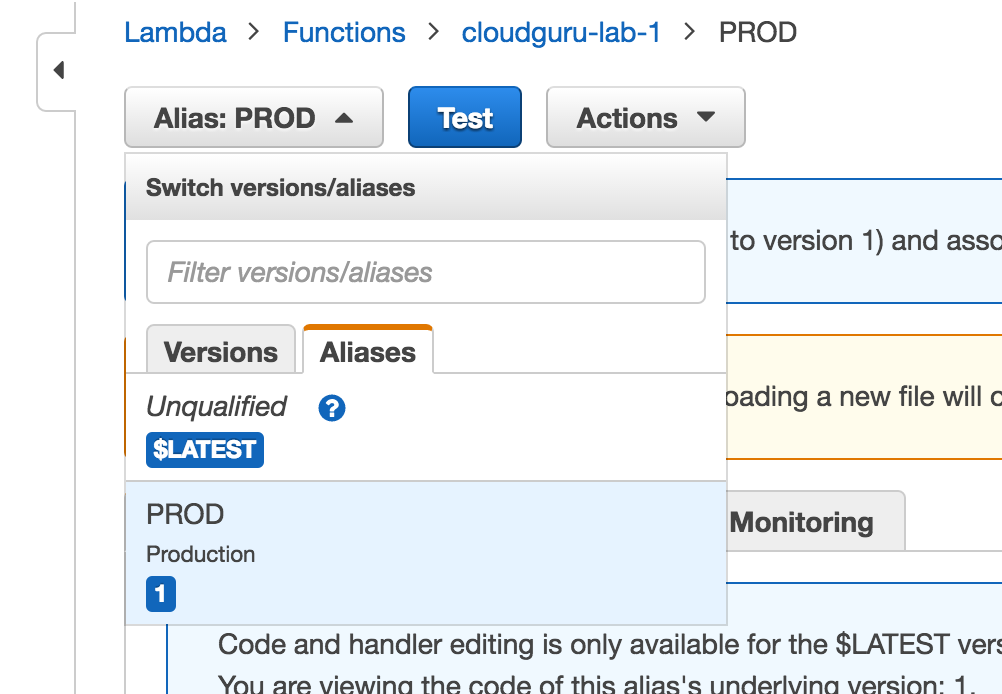
Versioning and Qualifiers
- Versioning through code upload
- Has unique identifier
- Qualifiers are named pointers that point to a given version
- e.g.
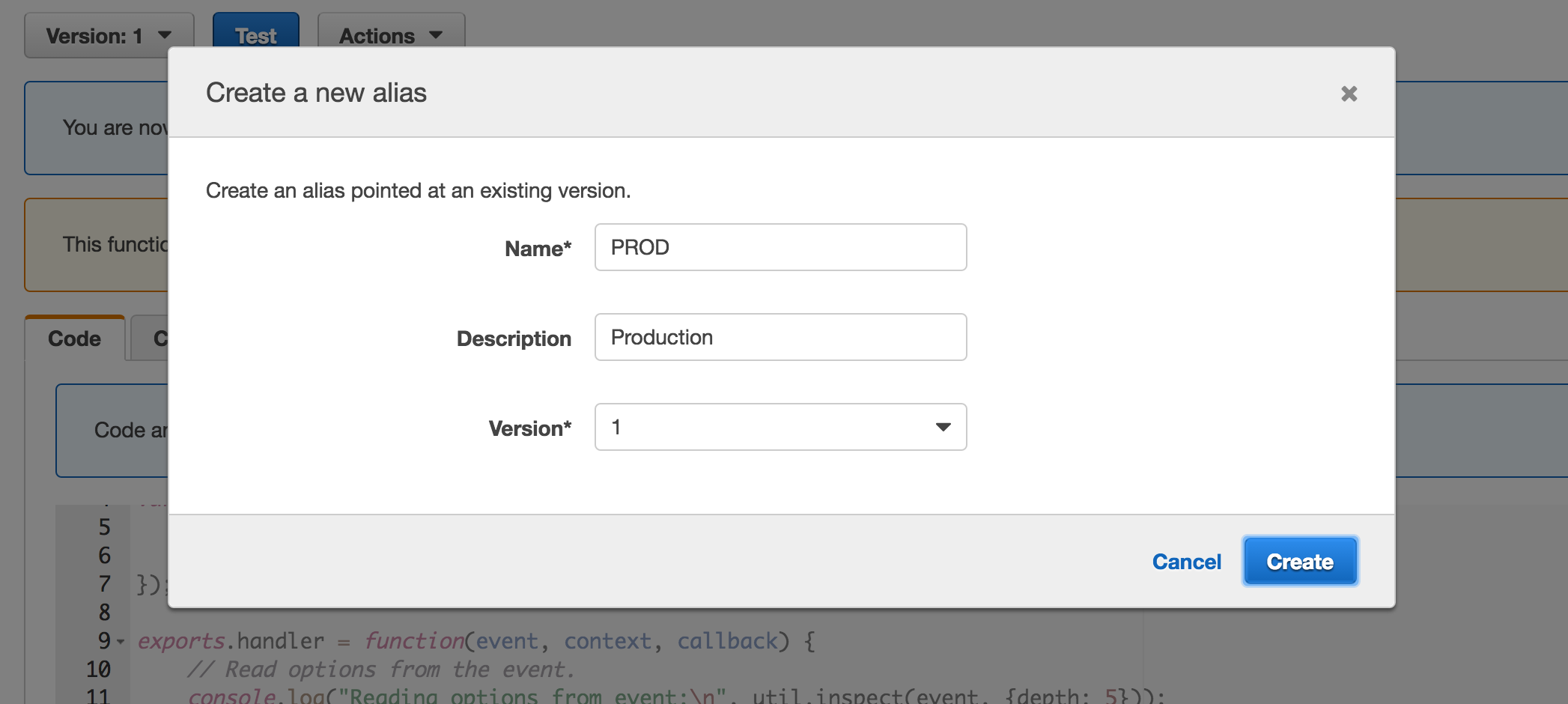
PRODpoints tov1
- e.g.
- Functions use
$latestby default
Can be used differentiate dev and prod environments and to differentiate different versions of functions.
These allow callers to invoke different versions of the function API until they update.
Upload code and publish:
aws lambda update-function-code --zip-file=fileb://csv_parse.zip --function-name cloudguru-lab-1 --publish
// result. Note version
{
"CodeSha256": "i364wBcJ4zZepGkWtOb/GvvEJrXBtY/k/wVLzSQ6fqU=",
"FunctionName": "cloudguru-lab-1",
"CodeSize": 1395,
"MemorySize": 128,
"FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-1:1",
"Version": "1",
"Role": "arn:aws:iam::592028804584:role/service-role/cloudguru-lab-1-role",
"Timeout": 3,
"LastModified": "2016-12-17T22:22:08.652+0000",
"Handler": "csv_read.handler",
"Runtime": "nodejs4.3",
"Description": ""
}
Creating an alias:
Alias definition:
Change files and release new version (using csv_sum rather than csv_read):
aws lambda update-function-code --zip-file=fileb://csv_parse.zip --function-name cloudguru-lab-1
aws lambda update-function-configuration --function-name cloudguru-lab-1 --handler csv_sum.handler
aws lambda update-function-code --zip-file=fileb://csv_parse.zip --function-name cloudguru-lab-1 --publish
// result from last command:
{
"CodeSha256": "k8TiiaoVCXDoA+bD585GRFhj9mUVlk6QWvsNMXxjXdo=",
"FunctionName": "cloudguru-lab-1",
"CodeSize": 1312,
"MemorySize": 128,
"FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-1:2",
"Version": "2",
"Role": "arn:aws:iam::592028804584:role/service-role/cloudguru-lab-1-role",
"Timeout": 3,
"LastModified": "2016-12-17T22:37:04.233+0000",
"Handler": "csv_sum.handler",
"Runtime": "nodejs4.3",
"Description": ""
}
Function ARN contains the version number: "FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-1:2"
Outputs
- Returned data is not stored but returned to the caller
- S3 isn't waiting for the output of your function. With it your function return is never used.
- In function you need to store the data that needs to be persisted
- Events don't receive output
- Events are async so the caller doesn't receive the return of the function
- API Gateway and direct invocations
- receive the output that you want them to receive.
In async invocations, the output is never stored.
Timeouts
Kill a function after it has gone over a certain amount of time.
context.getRemainingTimeInMillis()); is useful
Lab 2: Kinesis
Kinesis is an event streaming service.
Advantages
- Essentially a big log where all of the events are saved.
- Fast to write to and easy to read from. Can be read from a large number of subscribers.
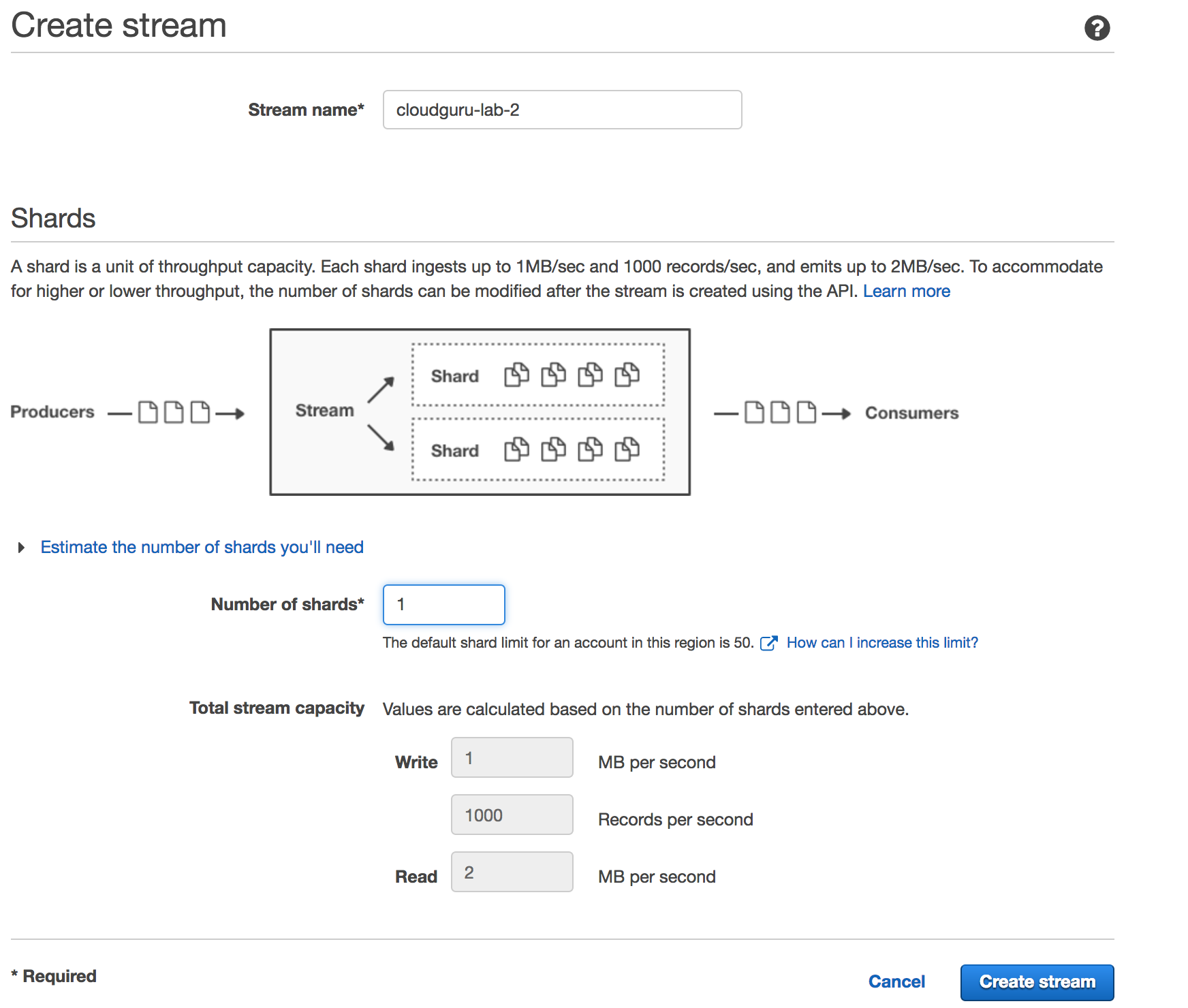
- clients can write up to 1 MB/sec or 1000 TPS (transactions per second) to an individual shard
- A Kinesis stream is actually a group of shards. You can add or remove shards to a stream at any time.
- Easy r eplay of data. Each shard retains the last 24 hours of events which can be replayed from the beginning at any time.
- Events are assigned to a shard.
- Lambda receives events that contain up to 100 records.
Setup
Triggers Setup:
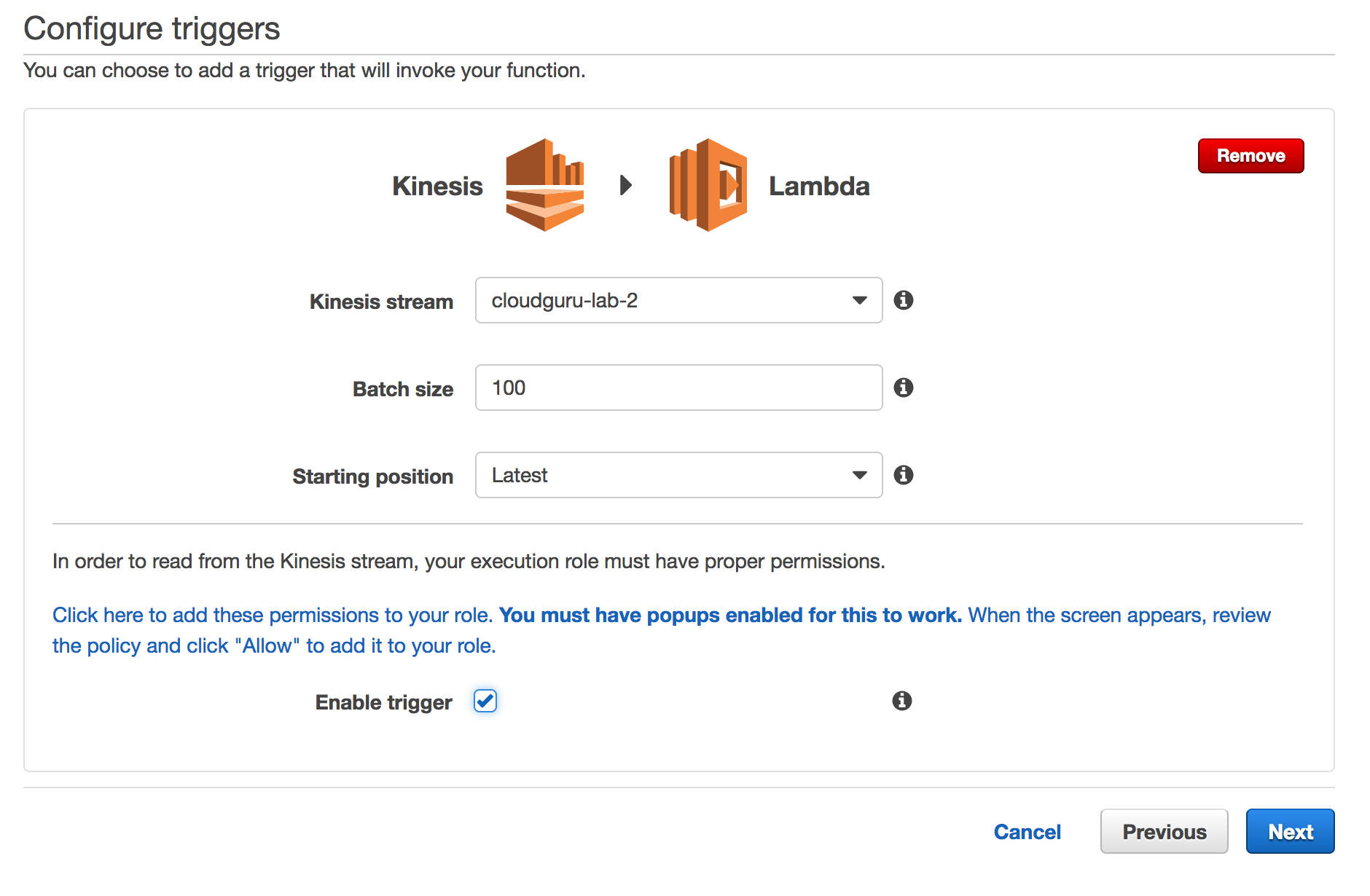
Starting position types:
- Trim Horizon: is what starts 24 hours ago. Contains all events up until now.
- Latest: no old events sent to function
- At Timestamp: Start reading from the position denoted by a specific timestamp, provided in the value Timestamp.
Click the link near enable trigger to add permissions to the role.
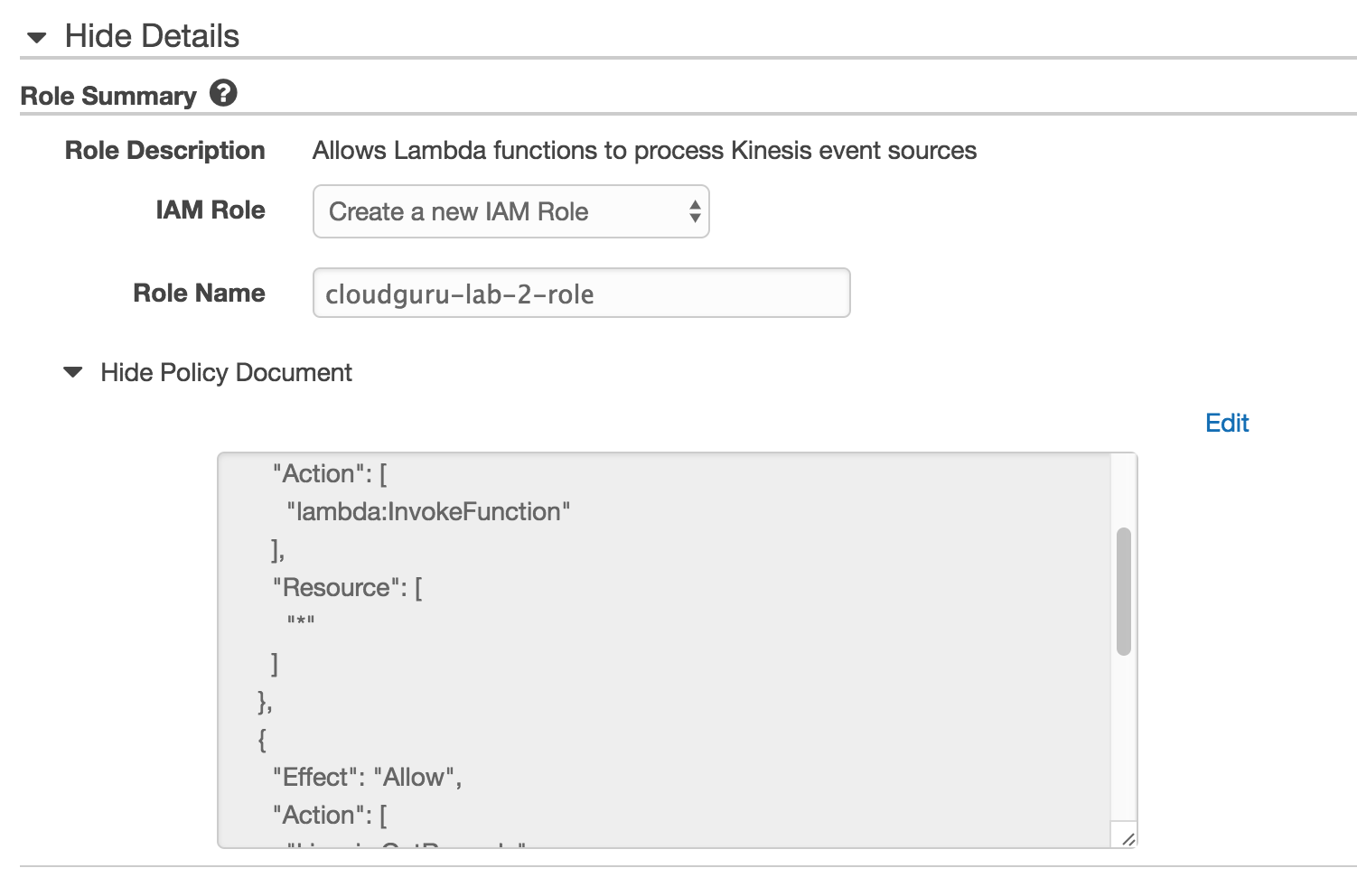
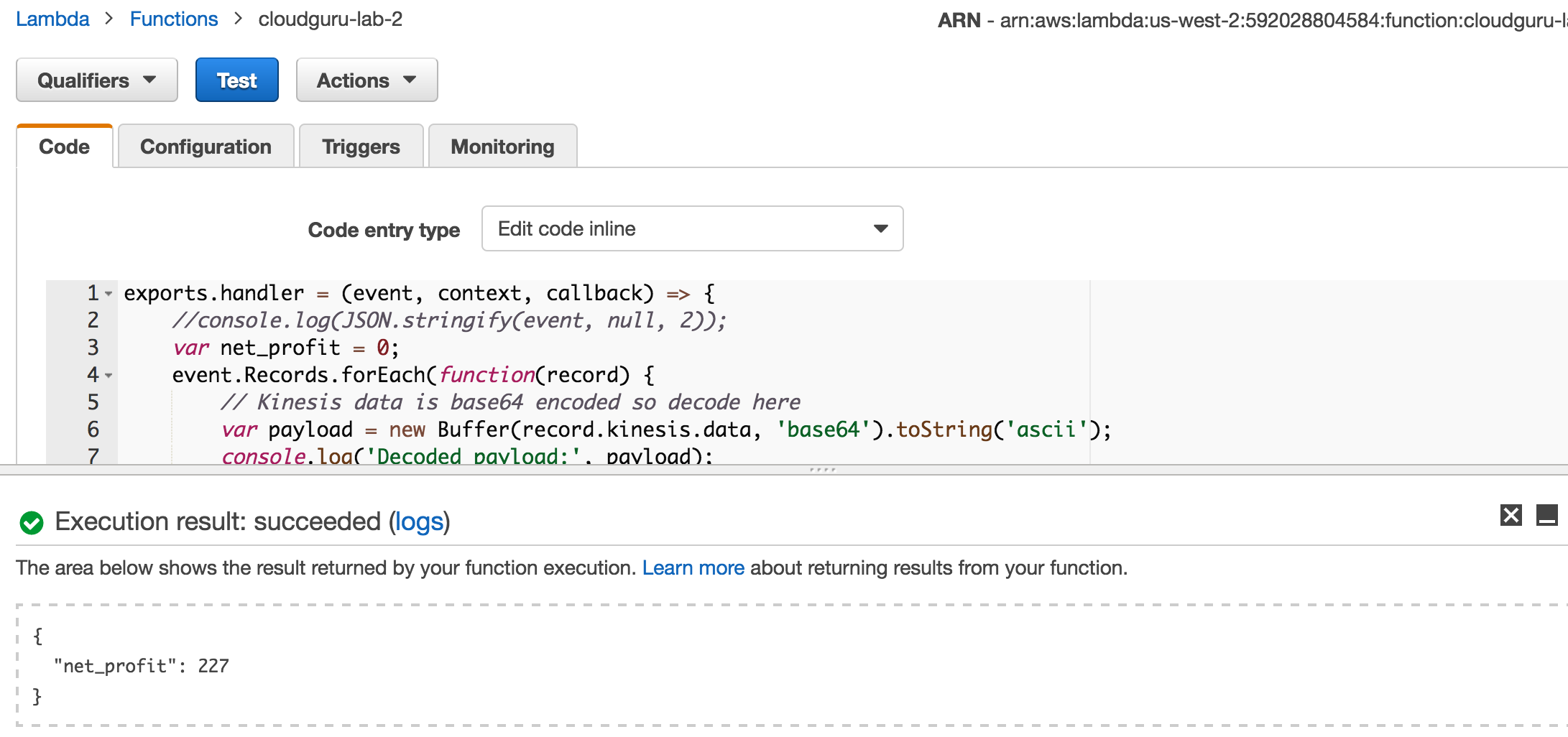
Function Code
aws lambda update-function-code --zip-file=fileb://kinesis_sums.zip --function-name cloudguru-lab-2 --publish
{
"CodeSha256": "SCjqNJK2vkKHllWgW2XU0gZqmfkcfHSDiDopsBLH/jg=",
"FunctionName": "cloudguru-lab-2",
"CodeSize": 477,
"MemorySize": 128,
"FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-2:1",
"Version": "1",
"Role": "arn:aws:iam::592028804584:role/cloudguru-lab-2-role",
"Timeout": 3,
"LastModified": "2016-12-18T03:42:47.360+0000",
"Handler": "index.handler",
"Runtime": "nodejs4.3",
"Description": "cloudguru lab 2"
}
Need to base64 encode data going into a Kinesis test event.
Test Records:
{
"Records": [
{
"eventID": "shardId-000000000000:49545115243490985018280067714973144582180062593244200961",
"eventVersion": "1.0",
"kinesis": {
"approximateArrivalTimestamp": 1428537600,
"partitionKey": "partitionKey-3",
"data": "MjAxNi0wNS0yNSw0NSw1MDAsMjcz",
"kinesisSchemaVersion": "1.0",
"sequenceNumber": "49545115243490985018280067714973144582180062593244200961"
},
"invokeIdentityArn": "arn:aws:iam::EXAMPLE",
"eventName": "aws:kinesis:record",
"eventSourceARN": "arn:aws:kinesis:EXAMPLE",
"eventSource": "aws:kinesis",
"awsRegion": "us-east-1"
}
]
}
Creating Kinesis Events
sample_records.json is the format for Kinesis records.
PartitionKey helps determine the shard.
[
{
"PartitionKey": "A",
"Data": "2016-05-26,90,9240,3947"
},
{
"PartitionKey": "B",
"Data": "2016-05-27,80,10389,2487"
},
{
"PartitionKey": "C",
"Data": "2016-05-28,102,1958,2498"
},
{
"PartitionKey": "D",
"Data": "2016-05-29,48,6853,1038"
}
]
Add records to Kinesis:
aws kinesis put-records --stream-name cloudguru-lab-2 --records file://sample_records.json
{
"FailedRecordCount": 0,
"Records": [
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49568663107732666464794712298413776610777864170559766530"
},
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49568663107732666464794712298414985536597478799734472706"
},
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49568663107732666464794712298416194462417093428909178882"
},
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49568663107732666464794712298417403388236708058083885058"
}
]
}
Saving records is an atomic operation and will be received by the subscribers. The saving can fail for some records but not all.
Lab 2: DynamoDB
Managed high-availability key-value store.
Key for this lab is the transaction id.
400kb limit per item.
Types such as lists, maps, and sets.
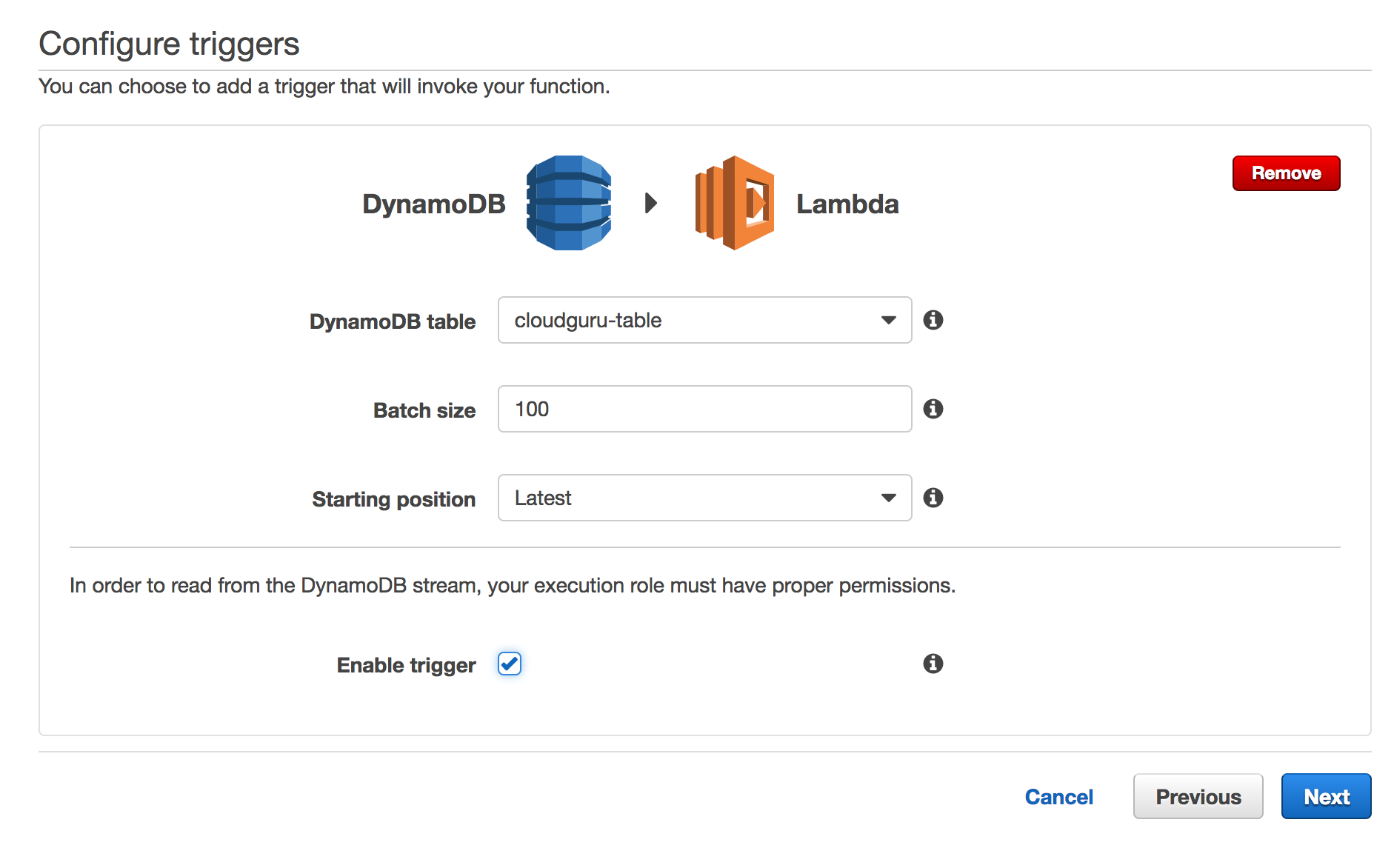
Dynamo DB triggers are a way to hook lambda functions up to events in a dynamo db table (created, deleted, modified records).
Events are batched. Event can include just the hash key or full object and possibly and old object.
Create a new table with primary key of txid.
Schemaless other than primary key.
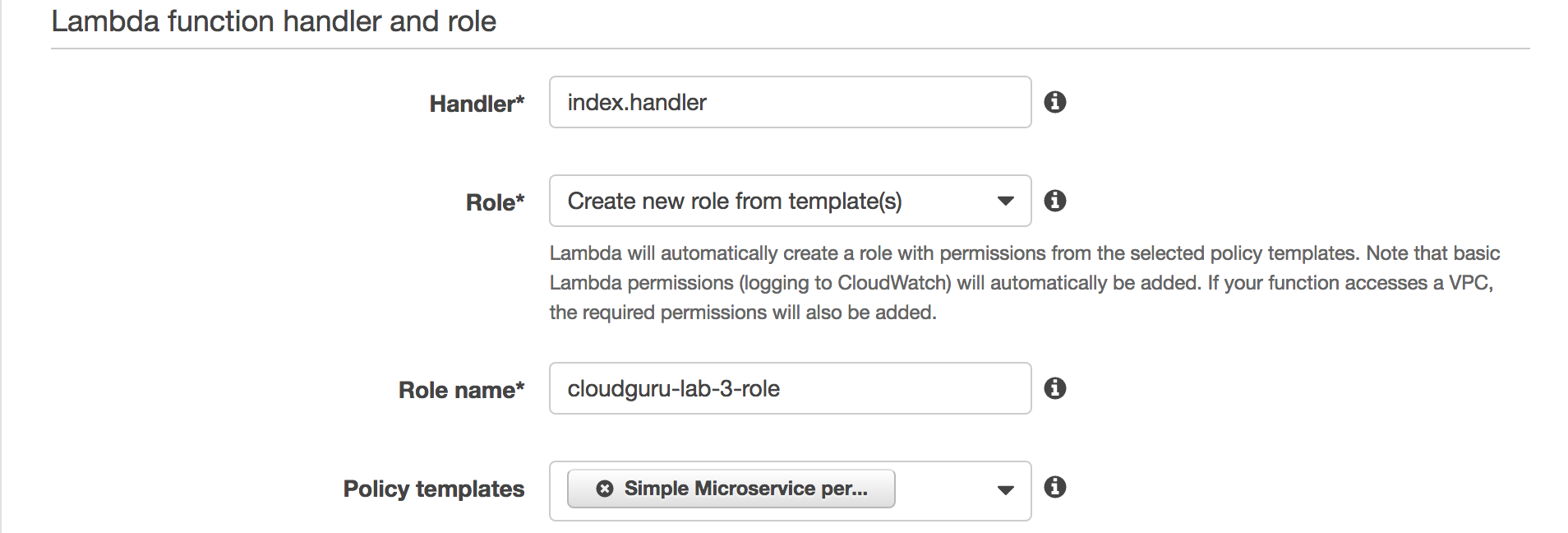
aws lambda update-function-code --zip-file=fileb://ddb_listener.zip --function-name cloudguru-lab-3 --publish
{
"CodeSha256": "AfTroFs89J10HmmMGHqBJvDRTS/rxCE4ShzYLqeMCdE=",
"FunctionName": "cloudguru-lab-3",
"CodeSize": 661,
"MemorySize": 128,
"FunctionArn": "arn:aws:lambda:us-west-2:592028804584:function:cloudguru-lab-3:1",
"Version": "1",
"Role": "arn:aws:iam::592028804584:role/service-role/cloudguru-lab-3-role",
"Timeout": 3,
"LastModified": "2016-12-18T05:27:50.082+0000",
"Handler": "index.handler",
"Runtime": "nodejs4.3",
"Description": "cloudguru lab 3"
}
Upload objects
aws lambda invoke --function-name cloudguru-lab-3 --payload "$(cat sample_event.json)" output.txt
Resources
- https://aws.amazon.com/blogs/big-data/from-sql-to-microservices-integrating-aws-lambda-with-relational-databases/
- http://docs.aws.amazon.com/lambda/latest/dg/vpc-rds.html
- AWS CLI Installation
- http://docs.aws.amazon.com/lambda/latest/dg/use-cases.html
- https://github.com/jaws-stack
- http://blog.contino.io/blog/5-killer-use-cases-for-aws-lambda
- http://docs.aws.amazon.com/lambda/latest/dg/programming-model-v2.html
- https://www.datawire.io/3-reasons-aws-lambda-not-ready-prime-time/
- https://serverlesscode.com/post/reader-question-future-of-lambda/
- http://stackoverflow.com/questions/36983138/are-there-any-performance-functionality-differences-for-aws-lambda-functions-wri
- https://github.com/berezovskyi/lambda-test
- https://github.com/anaibol/awesome-serverless
- https://medium.com/@quodlibet_be/aws-lambda-for-java-5d5e954d3bdf#.xge8y5flb
- https://serverlesscode.com/post/aws-lambda-limitations/